Tower
Introduction
Our bodies have various sensors that allow us to gather information from our surroundings and make decisions based on that input. These sensors include sight, smell, touch, taste, and hearing. We have similar sensors in technology that translate the real world into electrical signals. For example, a gas sensor mimics the sense of smell, a capacitive touch sensor replicates touch, a microphone corresponds to hearing, and a camera imitates sight, which is the focus of this discussion.
After collecting data from these sensors, we need to process it so the microprocessor can interpret it effectively. In the case of a camera, we can use algorithms and machine learning for tasks such as color detection, shape recognition, or even facial recognition.
OpenCV
OpenCV (Open Source Computer Vision Library) is an open-source software library for computer vision and machine learning. One of its key applications is face recognition. For this, we use a Cascade classifier along with a pre-designed database. The classifier's primary task is binary classification: determining whether an object is a face (1) or not (0).
Cascade classifiers are trained using positive samples (images containing the object of interest) and negative samples (arbitrary images of the same size that do not contain the object). Specifically, we use Haar cascade object detection. This method starts by isolating the face from the background using certain features, such as identifying the vertical line of the face by recognizing the contrast between "light" skin and the background.
This process is efficient because once the supposed face boundaries are identified, additional methods, like eye detection, are employed. A key characteristic of human faces is that the eye region is typically darker than the nose and cheeks. By applying a white-black-white marker, we obtain new data to compute using weights gathered during training. Another crucial feature is that the eyes are darker than the bridge of the nose.
By proceeding step by step, we save a significant amount of time, which is vital for real-time face recognition. Overall, there are more than 6000 features, each weighted differently. Describing all of them would be impractical, but for a more detailed explanation, you can refer to this article.
Mediapipe
For real-time gesture recognition, I use a library called Mediapipe. Initially, it detects the palm's location using an algorithm similar to the one used in face recognition. This optimization helps streamline the computation of the entire gesture. Once the hand is located and enclosed within a bounding box, the next step is identifying specific points on the hand. Our model is trained to search for 21 landmarks.
Even if the model doesn’t see all the points or the hand is partially visible, it can predict their positions by leveraging its understanding of the hand's consistent internal pose representation. The model has learned how a typical hand appears, with five fingers, four extending almost straight from the palm and one slightly rotated (the thumb). It functions similarly to our brain, which can predict the location of fingers even if they are not fully visible, like when someone shows a thumb-up gesture.
"After palm detection over the whole image, our subsequent hand landmark model performs precise keypoint localization of 21 3D hand-knuckle coordinates inside the detected hand regions via regression, that is, direct coordinate prediction." (Source: Mediapipe Hands Documentation)

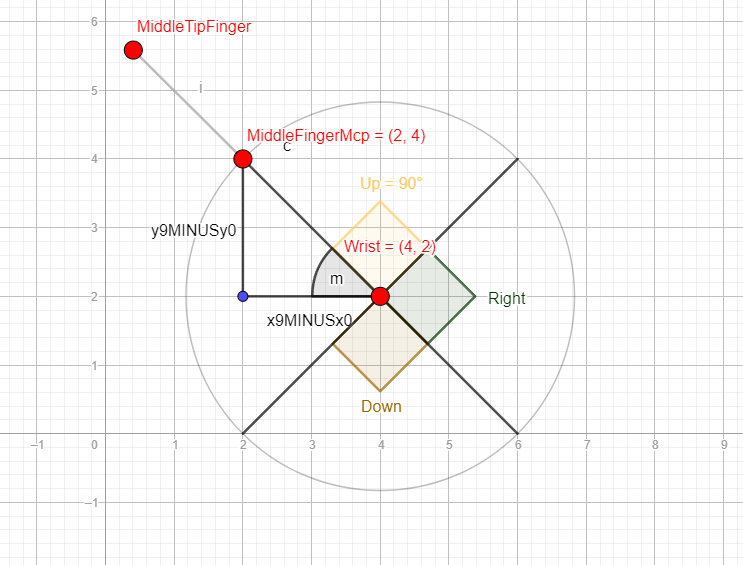
And now the question arises: how can a computer recognize gestures with just a few coordinates? The answer is simple: mathematics. By knowing the positions of key points such as the wrist (0) and the middle finger MCP (12), we can determine if the hand is facing "Up," "Down," "Right," or "Left."
First, we calculate the absolute value of the x-coordinates and check if this value is close to zero (\(|x_9-x_0|\)). This step is crucial for further calculations involving the tangent, because \(\tan({90^{\circ})\to \infty}\) approaches infinity. If the absolute value is not close to 0 (i.e., greater than 0.05), we proceed to calculate the tangent of our absolute values (\(m = |{{y_9-y_0} \over {x_9-x_0}}|\)).
Next, we check if our m value is greater than 1. If it is, the hand is facing either "Up" or "Down." To determine the exact direction, we compare the y-coordinates of our points. Assuming a Cartesian coordinate system with the origin at the bottom-left corner, we can use the following logic: if \(y_9>y_0 \), the hand is facing "Up"; if \(y_9<y_0\), the hand is facing "Down."
However, if our m value is less than or equal to 1 and greater than 0, the hand is pointing either "Left" or "Right." To determine this, we compare the x-coordinates: if \(x_9>x_0\), the hand is pointing "Right"; if \(x_9<x_0\), the hand is pointing "Left."
x0 = coordinate_landmark_0[0]
y0 = coordinate_landmark_0[1]
x9 = coordinate_landmark_9[0]
y9 = coordinate_landmark_9[1]
if abs(x9 - x0) < 0.05:
m = 1000000000
else:
m = abs((y9 - y0)/(x9 - x0))
if m>=0 and m<=1:
if x9 > x0:
return "Right"
else:
return "Left"
if m>1:
if y9 < y0:
return "Up"
else:
return "Down"
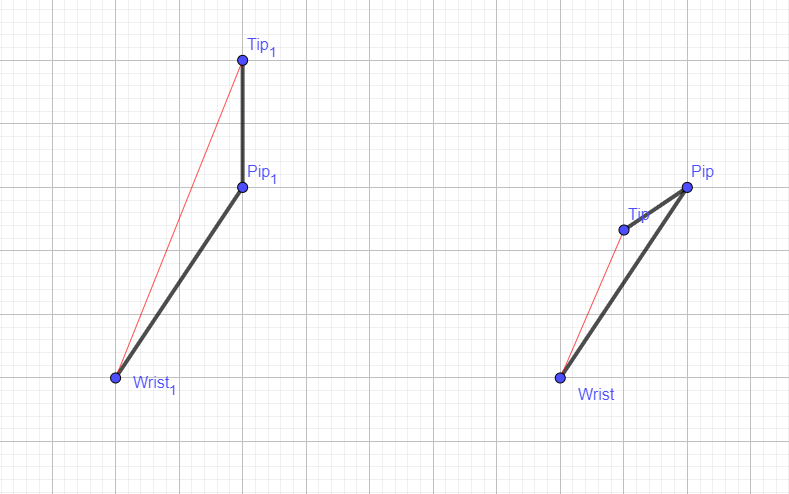
Other gestures, like "thumbs-up," "point," "fist," or "pinch," can be recognized by checking which fingers are folded. To determine if a finger is folded, we use landmarks on different parts of the finger: the tip, PIP (proximal interphalangeal joint), and wrist. By measuring the distances between the tip and wrist, and between the PIP and wrist, we can determine the finger's state.
If the distance from the tip to the wrist is greater than the distance from the PIP to the wrist, it means the finger is unfolded (tip-wrist > pip-wrist = "finger is unfolded"). Conversely, if the distance from the tip to the wrist is less than the distance from the PIP to the wrist, the finger is folded (tip-wrist < pip-wrist = "finger is folded"). This method allows us to understand various gestures.
For example, in a "thumbs-up" gesture, the pinky, ring, middle, and index fingers are folded, while the thumb is extended. In programming, we can represent this by assigning values to each finger: 0 for folded and 1 for unfolded(in this example, would be thumb-1).
p0x = landmarksCords[0][0] # coordinates of landmark 0 "Palm"
p0y = landmarksCords[0][1]
p5x = landmarksCords[5][0] # coordinates of landmark 5
p5y = landmarksCords[5][1]
p3x = landmarksCords[3][0] # coordinates of mid thumb finger
p3y = landmarksCords[3][1]
d03 = dist([p5x, p5y], [p3x, p3y])
...
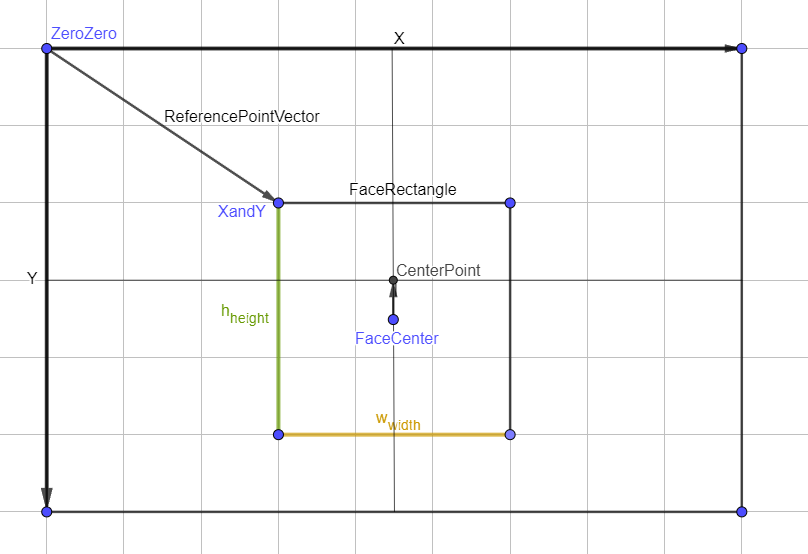
Face position and Camera Adjustment Math
Once we have detected the desired face, we need to determine its position relative to our video display (window) and adjust the camera's direction accordingly. Using OpenCV, we can easily detect the face and draw a rectangle around it. To find the estimated center of the face, we take the width and height of the rectangle, divide each by two, and add the respective x and y coordinates of the rectangle's top-left corner.
Here's how to calculate the center of the face in the video frame:
1. Calculate the center of the face:
-
\(X_{FaceCenter}=x+\frac{w}{2}\)
-
\(Y_{FaceCenter}=y+\frac{h}{2}\)
2. Adjust for the video frame center:
- \(X_{Center}=\frac{VideoWIDTH}{2}\)
- \(Y_{Center}=\frac{VideoHEIGHT}{2}\)
3. Determine the face's position relatively to the frame center:
- \(\triangle X=X_{FaceCenter}-X_{Center}\)
- \(\triangle Y=Y_{FaceCenter}-Y_{Center}\)
XFaceFcenter = x + w / 2 - Xcenter
YFaceFcenter = y + h / 2 - Ycenter
By calculating these values, we can determine how far the face is from the center of the video frame and adjust the camera's position accordingly to keep the face centered.
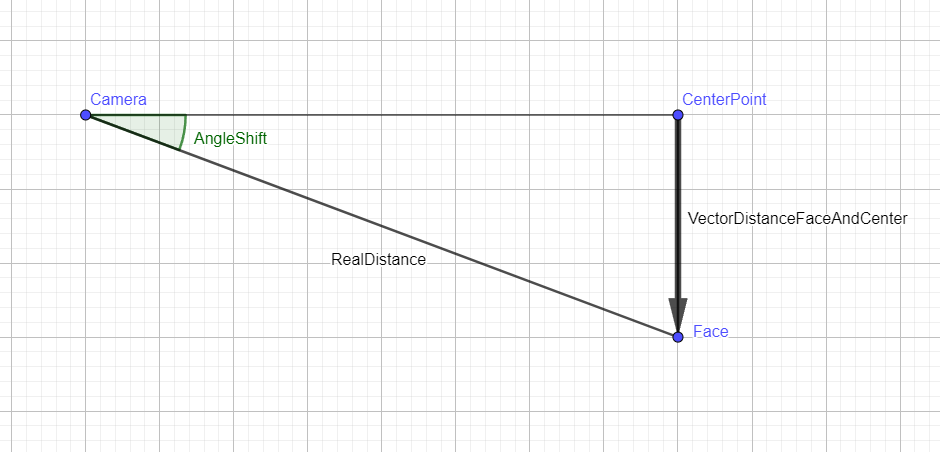
To adjust the camera's position to center the face, we calculate the horizontal and vertical angles based on the vector distance between the face center and our desired center point. Because the camera adjusts by rotating horizontally and vertically, we need to determine how many degrees it should move in each direction.
1. Calculate the vector distance:
- Let \(\triangle X\) be the horizontal distance between the face center and the desired center point.
- Let \(\triangle Y\) be the vertical distance between the face center and the desired center point.
2. Convert distance from pixels to real-world units (cm):
- Using optics principles, we apply the lens equation modification: \(x = \frac{h}{H}*y\)
- \(x\) is the distance in centimeters from the camera to the face (desired distance).
- \(h\) is the actual width of the face (approximately 15 cm for an average face).
- \(H \) is the width of the face on the video (in pixels).
- \(y\) is the focal length of the camera, a fixed value.
- Therefore: \(x=\frac{15*y}{H}\)
distance = (actual_width * focal_length) / w
3. Calculate the angle to move the camera:
- Convert the horizontal and vertical distances to angles using the inverse sine function:
- \(\theta_{horizontal}=sin^{-1}(\frac{\triangle X}{x})\)
- \(\theta_{vertical}=sin^{-1}(\frac{\triangle Y}{z})\)
horizontalAngle = round(np.arcsin(np.absolute(actual_width * XFaceFcenter / w) / distance) * 180 / np.pi * 0.75, 2)
verticalAngle = round(np.arcsin(np.absolute(actual_width * YFaceFcenter / w) / distance) * 180 / np.pi * 0.75, 2)
These angles determine how much the camera needs to rotate horizontally and vertically to position the face at the desired center point in the real world, considering the optics and physical distances involved.
Multiprocessing for Smooth Camera Movement
To achieve smoother camera movement, I implemented multiprocessing, which allows the system to handle multiple tasks simultaneously. With multiprocessing, the CPU can execute several processes concurrently, enabling simultaneous control of two servos. Without multiprocessing, the camera would move sequentially: first horizontally and then vertically. This sequential movement isn't efficient and can result in jerky, stair-like motions.
By using multiprocessing, the camera can move both servos simultaneously. This allows the system to choose the fastest path, typically diagonal movement, which results in smoother transitions between horizontal and vertical adjustments.
t1ServoX = threading.Thread(target=self.write_servo, args=(round(currentPosition_x, 1), 14))
t2Servoy = threading.Thread(target=self.write_servo, args=(round(currentPosition_y, 1), 15))
t1ServoX.start()
t2Servoy.start()
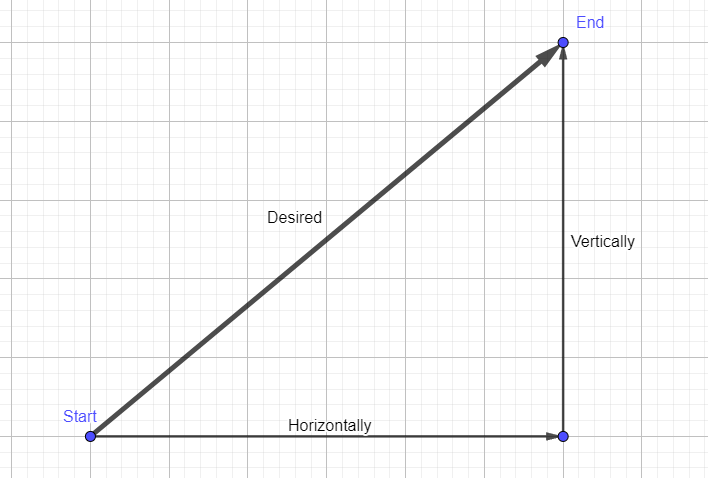
To enhance the smoothness of the camera's movement, I implemented acceleration and deceleration for the servos. This technique ensures that the velocity along the path from the starting to the ending point follows a parabolic curve. I chose this method because it optimizes efficiency and minimizes abrupt changes in speed.
Here's why this approach is effective: simply slowing down the servo's steps would result in lag during face tracking. Alternatively, not smoothing the movement would lead to erratic shaking and rapid shifts from side to side, disrupting the entire system's stability.
By incorporating acceleration and deceleration, the servo movements are not only smoother but also more controlled. This allows for precise tracking of the face without sacrificing speed or stability.
targetValue = angle
diff = targetValue - currentValue
for t in range(20):
y = (-3*diff/4000)*t**2 + (3*diff/200)*t
currentValue += np.round(y, 2)
my_servo.angle = currentValue
time.sleep(.01)
Hardware Setup
Microprocessor:
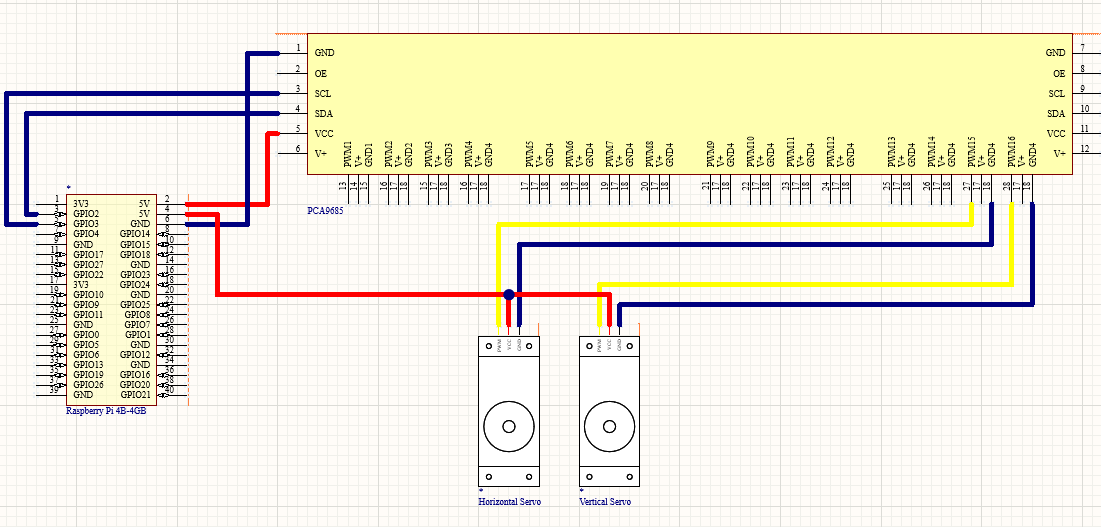
For this project, I chose to use the Raspberry Pi 4B with 4 GB of RAM. It features a Quad-core Cortex-A72 (ARM v8) 64-bit SoC running at 1.8 GHz and includes a 40-pin GPIO header. This setup provides ample computational power for real-time face and gesture recognition, as well as streaming live video output.
Camera:
I opted for the IMX519 camera module, which offers a resolution of 16 MP with active pixels of 4656x3496 and a pixel size of 1.22μm×1.22μm. One of its notable advantages is autofocus capability, which will be beneficial for future stages of the project. The camera can achieve high frame rates, up to 120 fps at 1280x720 resolution (although our usage will likely be lower due to the computational demands of face and gesture recognition). Details on connecting this camera to the Raspberry Pi can be found here.
Servo control:
To control the servos, I selected the PCA9685 16-channel servo driver. While 16 channels may initially seem excessive for controlling two servos, this setup allows for scalability in future expansions of the project, such as integrating with a full robot dog. The additional channels will be useful for managing multiple servos and ensuring a streamlined control system.
Servo:
For servo actuators, I opted for the Miuzei Micro Servo Metal Gear 90 9G. These servos are known for their reliability, and the use of metal gears minimizes the likelihood of steps being skipped during rotation. This ensures precise control over the camera's positioning.
Mechanical Assembly
To create the parts, I decided to print them using my Ender 3, 3D printer. Printing them will ocure in easy manufacturing and are lightweight. You can find the printing files and details such as temperature, infill, and support settings here.

1. Servo Installation:
- Place the servo inside the body, ensuring the cables are routed through prepared holes.
2. Attaching Tower Feet:
- From the bottom, screw the plastic servo horn into the "tower-feet" component.

3. Assembling the Tower Head:
- Combine the tower head bottom and top parts, ensuring the camera and servo are securely inside and connected. For easier setup, secure it from the top using M3x5mm screws (note: the bottom part houses the camera cable output).

4. Servo Calibration:
- After everything is connected, calibrate all the servos. You can do this manually or use the
servo_calibration.pyscript from my repository. Ensure the camera faces the correct direction at 0 degrees (starting position shown in the first picture of this chapter).
5. Mounting the Head to the Body:
- Insert another plastic servo horn into the top of the "body," opposite the rounded hole.
- Carefully mount the head into the body, applying gentle pressure. If necessary, use glue to secure any broken parts.

Finall result


Software Setup
To run the Python code on your Raspberry Pi, which operates on Raspbian (based on Debian GNU/Linux), follow these steps to set up the environment and dependencies:
1. Update and Upgrade:
- Connect your Raspberry Pi to a screen via HDMI. Open the command line interface and execute:
sudo apt update && sudo apt full-upgrade
2. Install IMX519 Camera Dependencies:
- Install the necessary dependencies for the IMX519 camera module. Follow the instructions here.
sudo apt reboot
3. Camera Test:
- Verify if the camera works by capturing a still image:
libcamera-still -t 5000 -n -o test.jpg
4. Install Python Libraries:
- Install Python libraries required for camera operations and general development:
sudo apt install -y python3-picamera2
sudo apt-get install cmake && sudo apt install git && sudo pip3 install virtualenv
5. Clone and Setup Repository:
- Clone the repository containing your Python project and navigate into its directory:
git clone https://github.com/Marcel3245/Tower.git && cd Tower
6. Create abd Activate Virtual Environment:
- Set up a virtual environment with system site packages and activate it:
python3 -m venv --system-site-packages venv
source venv/bin/activate
7. Install Required Packages:
- Install all necessary Python packages specified in '
requirements.txt':
pip install -r requirements.txt
8. Prepare for Face Analysis:
- Navigate to the training directory and prepare for face image capturing and training:
cd training
python training_picture.py
python face_training.py
9. Servo Calibration:
- Assuming all hardware components are connected and set up, calibrate the servos:
cd ~/Tower
python servo_calibration.py
10. Run the Application:
- Launch your application for face and gesture recognition:
python towerV3.py
Follow these steps to set up and run your project on the Raspberry Pi, enabling face and gesture recognition capabilities using the IMX519 camera and servo-controlled mechanism. Good luck!
Looking forward, the next phase of this project involves integrating the tower into a robot dog design that responds to gestures. This step will enhance functionality and interaction capabilities significantly. For now, I recommend exploring additional publications and resources to gather more ideas and insights. If you have any further questions or need assistance, feel free to reach out in the comments.
Here are all the needed components of the project:
Comments
Karl
- 18 June, 2024
Really interesting!!
Leave a comment